Twitter System Design

Hi, I'm Basel Rabia, a Backend Web Developer , Passionate and always doing my best with the aim of improving operational functionality, interested in Laravel, Node.js, NoSQL, Golang
Step1: Requirements and goals
Twitter is a two-sided network so you have people creating tweets and People consuming the tweets so break up the system diagram into these two halves so let's start with some of the core
Functional requirements
1. creating a tweet: Being able to create a tweet.
2. generating the timeline for the user: for someone who's following different people to be able to view all the tweets of his following.
3. Follow people: being able to follow people.
4. Interact with tweets: in terms of adding replies or making a like.
Non-functional requirements
1. optimize for reads: when we look at Twitter, it's going to be a read-heavy system cause there will be more people reading and viewing the tweets than writing.
2. optimize for influencers: someone from celebrity people who had millions of followers writing a tweet would we want to make sure that if there they create a tweet, It doesn't bring the system down.
3. high availability is over consistency: we want the system to be very highly available versus that if a user created a tweet you don’t need to necessarily have the tweet available to everyone to consume it in real-time there could be a few seconds lag between creating a tweet and being able to read and interact and I would say Eventually consistency.
4. low latency: in terms of when it comes to generation of the timeline.
More Requirements would have to do also,
1. Adding more videos images to tweets makes the tweets more graphically rich.
2. Editing a tweet I know Twitter doesn't offer that but that's like one of the most requested features.
3. Retweeting with a comment without a comment.
Step2: Defining Data Model (our scope)
- creation of the tweet.
- generation of the timeline.
- follow people.
- interacting with the tweet.
1- Create a tweet (Endpoint)
POST /tweet/create
Body {
Text: ” “
}
the body of the post would essentially contain the tweet, the text over here is the tweet itself.
2- Retrieve the timeline (Endpoint)
GET /getTweets
the response over here would be in a paginated manner let's say the first top 20 tweets come on to your Timeline.
3- follow people (Endpoint)
so you would say follow then you could pass in the user.
POST /follow
Body {
follower_id: 15
}
the follower id over here who you want to follow and your user id kind of is sent as a part of the header.
4- like a tweet (Endpoint)
POST /tweet/{tweet_id}/like
you make a like reaction to this specific tweet with tweet id.
5- reply to a tweet (Endpoint)
POST /tweet/{tweet_id}/reply
Body {
Text: ” “
}
the text is your response to the tweet.
U need to know what the tweet id is there to tell you which tweet you are responding to so these are at a high level like these APIs that you have.
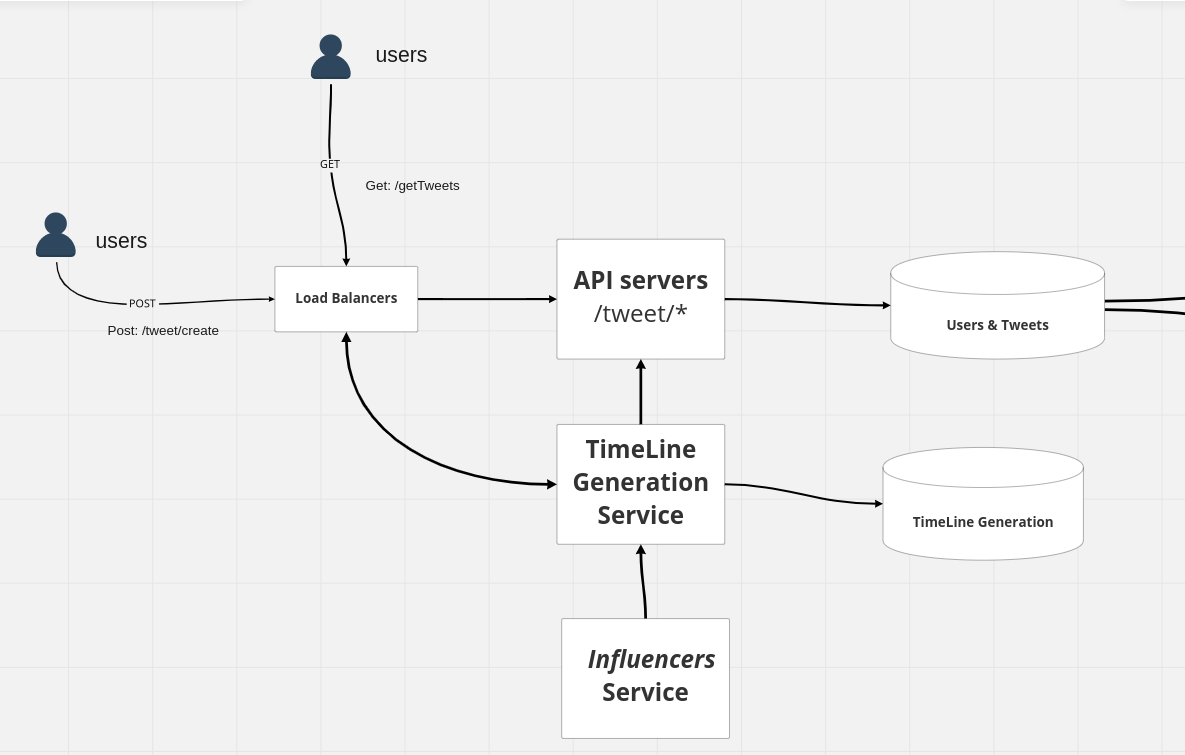
Step3: High-Level Design (system overview)
let's start off with the creation of a tweet
you have your users over here with any large system
what scale Twitter is, you tend to have load balancers in the middle
because it's a distributed system geographically, you will have multiple hundreds if not thousands of servers serving the millions of users
you have load balancers now.
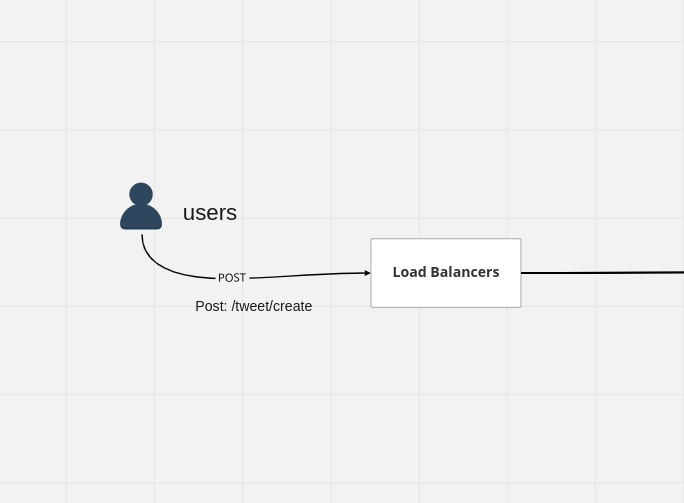
in terms of creating the tweet, you are essentially with HTTP POST you are calling this endpoint /create/tweet
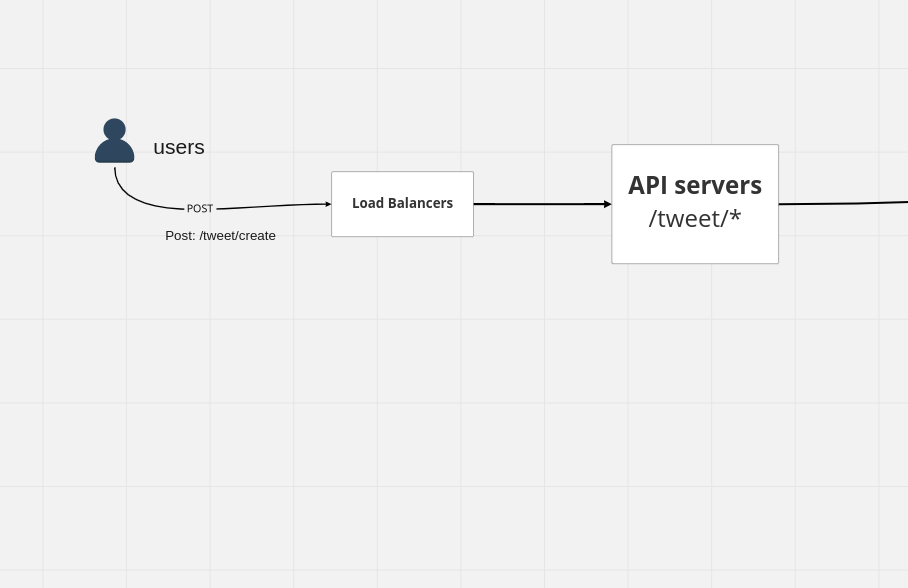 So there are a bunch of servers over here that you can call your API Servers handling these endpoints
So there are a bunch of servers over here that you can call your API Servers handling these endpoints
so basically anything to do with the tweets whether it's the creation, replies, like everything would essentially be handled by these APIs right these so anything with /tweets
Q: How would you Distribute the load from the Load Balancers to all the different, let's say you have N Servers, How would you know which server to send it to?
there are a few systems mechanisms over here, so something as simple as a round robin mechanism could work, you could look at some kind of a consistent hashing system where every server is a hash and then you round-robin on the Hash to distribute this geographically.
so let's say I am in the US and I send a post to create a tweet so the load balancer would route this to any of the US data centers where let's say somebody in Asia or somebody in the EU is doing a similar action they would probably get routed to a data center that is close to their geography so you could kind of choose to do them in one of these n numbers of ways this would kind of create the tweet.
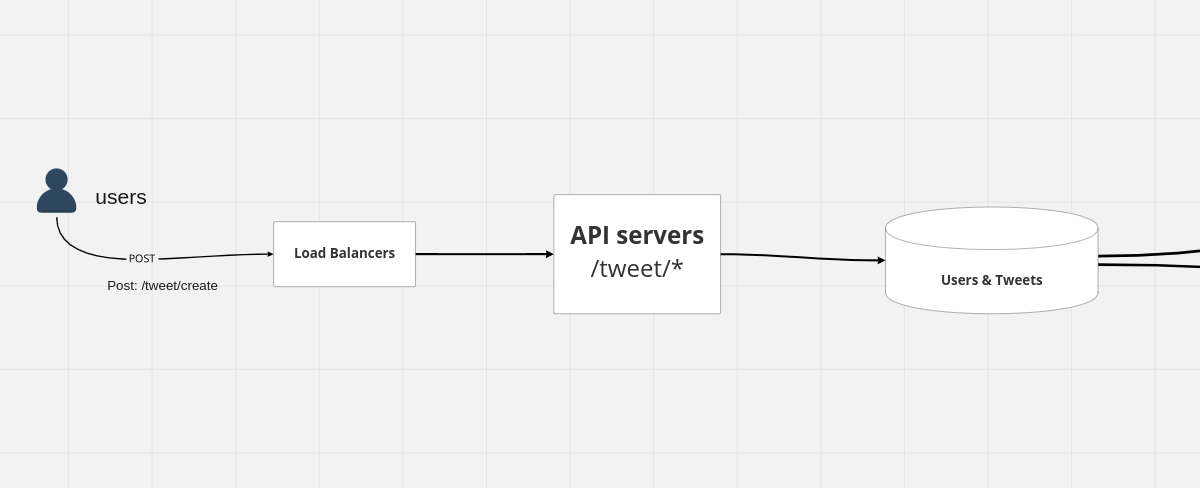
and we would have a SQL database over here where all the user's tweets are stored so you have your users and you have your tweets.
so these are your main two entities in terms of the database that you have.
Step 4: Detailed Design
Dig deeper into two or three components, we can get into the database details a little later on, Now Tackle is
Generation of tweets
so if you look at it one very simple brute force way, is that in your database, you have your tweets table for a given user, if they come to call the gets tweets endpoint, will be a query that scans the entire tweets tables and removes them to the most top like if you're looking at chronological order, top 20 tweets or this n number of tweets for this particular user it's simple in implementation.
Downside of this brute force way is as your tweet table grows over time these queries will get very expensive and it'll cause very high latency in terms of getting the timeline.
To keep the latency low we want to optimize for reads there has to be some kind of pre-computation that we need to do in terms of the generation of the timeline itself.
Q: How are we gonna pre-computation the timeline?
When tweets are coming in there is correspondingly a timeline generation service,
it will map all the users then we can optimize this service for generating the timelines for your most frequent user so let's say your daily active users , we want to generate a timeline for our daily or our weekly active users by seeing who is viewing twitter once a month or once every six months, we maybe do not compute the timelines for them
because that'll just be a waste of computational power.
so we are optimizing for our daily active users whenever a tweet comes in along with storing it into the database.
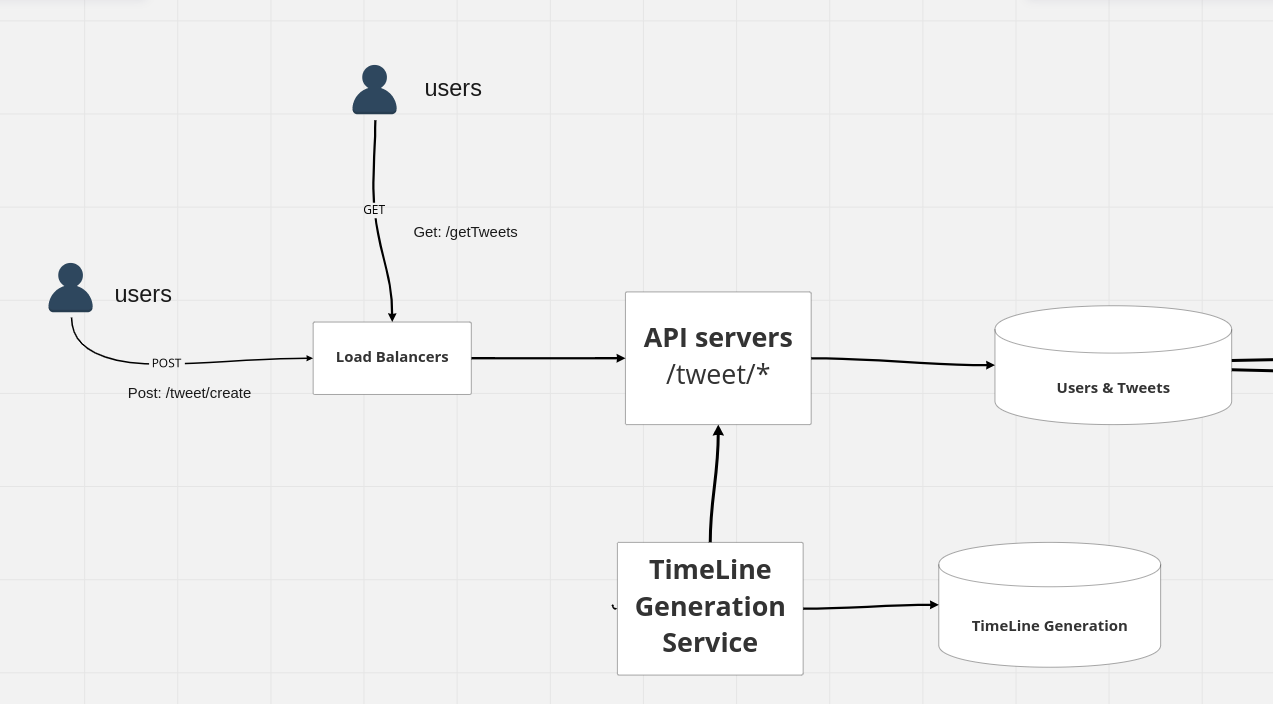
Q: What is this timeline generation service doing?
for every user, it's looking at that tweet and saying, Does this tweet belongs to this user's timeline all right, Does it belongs to one of the people that this user is following if yes it adds it to the person's timelines on the top so it's kind of a Stack where it keeps adding the
tweets to the top.
Optimize for influencers
The downside for this kind of system is that somebody who probably has 50 or 60 million followers if she does a tweet you are essentially recalculating the timeline for 50 million people for that one tweet, which computationally is very heavy and very redundant in nature.
Q: what we can do for this set of influencers who have this high bar of users?
we don't do the timeline we don't update the timeline of those 50 million followers, but if when a user basically requests this so let's say another user over here is requesting that tweet, so you're doing the GET /tweets then our load balancer is calling this timeline generation service, while the timeline generation service gets the request out at runtime,
it will take something from your influencer's service And add that data to your response on the fly, while the service is responding back it will add this data on the fly or at run time and send out the timeline to the users so this way you're not populating the timeline for these large set of users for these one-off tweets sent by influencers.
 We have talked about all these different types of users
We have talked about all these different types of users
- highly active users.
- less active users.
- influencers, or celebrities.
Two Ways for generating a timeline
there are two ways that you can generate someone's timeline like a pull or push method.
Q: Why we would recommend a pull method or a push method For getting someone's timeline?
it needs to be a hybrid approach over here,
- somebody who's your very daily active user who's visiting your app or the website very frequently I think a push model for them would be more effective.
- but someone who's visiting Twitter not so frequently after a long time, I think we would use a pull model for them, it would be more effective.
pushing content to less active users when they're not accessing it would not make sense so we want to look at analytics data to see which users you would want to push data to whereas which users would pull data depending on their usage.
Being Highly Available
a lot of these services over here would be replicated so you don't have one server you have multiple servers doing this and in terms of our database as well, you have multiple instances in some kind of a master-slave configuration where you know these databases can be duplicated right.
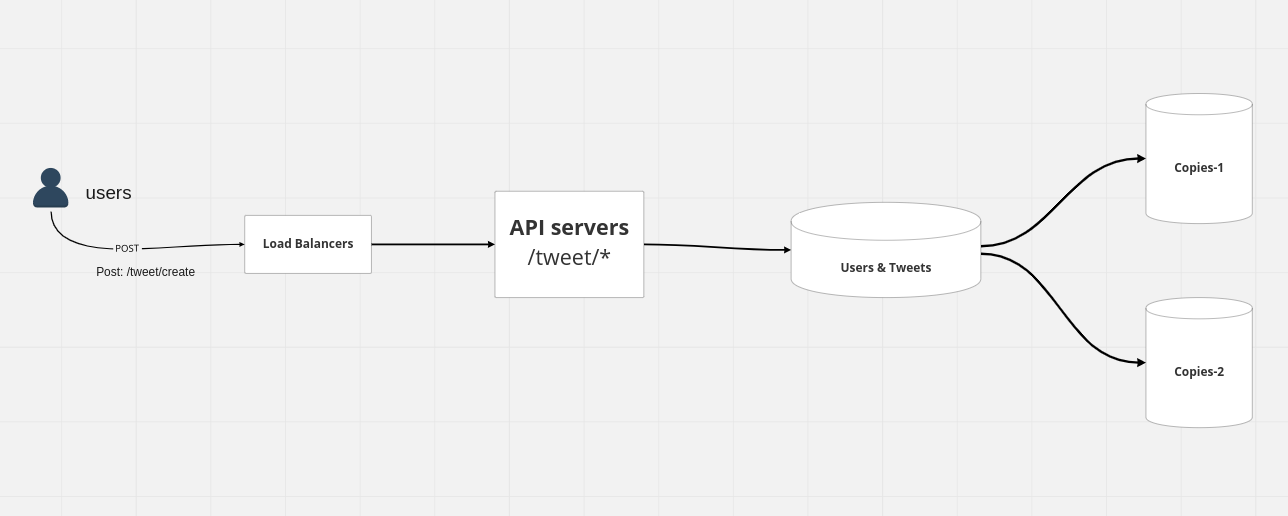
so basically as Your tweets go out they get kind of duplicated over here, so like these are copies of your master database here so this kind of makes sure that even if something goes down in one of the data centers or one of the databases, you can have backup copies stored.
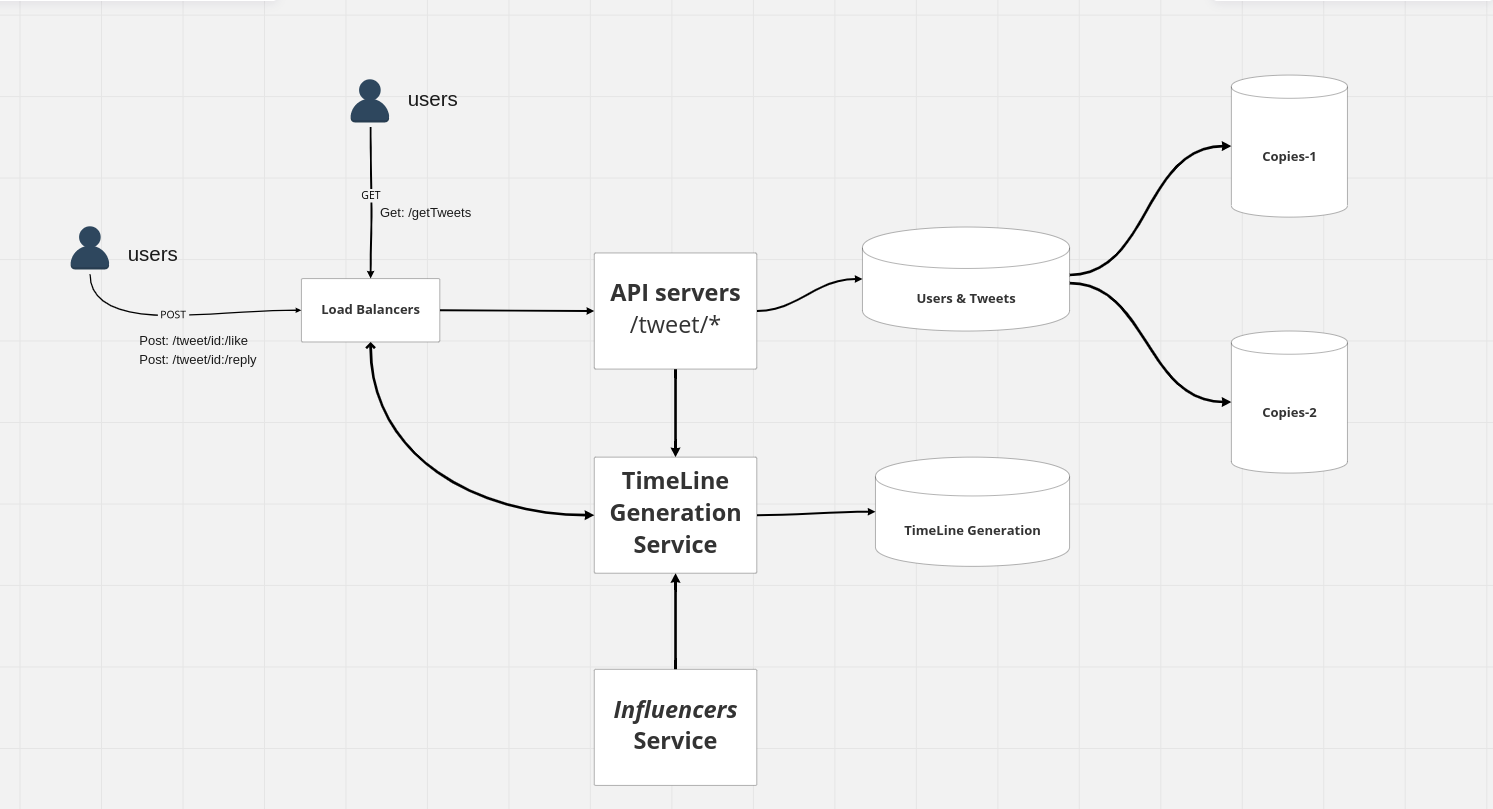
Interaction with the tweets
it follows a very similar process where essentially you the users are sending a
POST /tweet/{tweet_id}/like (endpoint)
OR
POST /tweet/{tweet_id}/reply (endpoint)
And essentially the idea here is that along with the payload they get forwarded to the load balancers and kind of get handled by the API servers over here, it follows the same mechanism as that of the regular tweet, and one important consideration here is that we are encountering in the use cases that the tweets are just pure text, we have not accounted for use cases where tweets could be an image or a video, we would kind of need to have a separate kind of storage to store those images and videos and then push them onto some kind of CDN (Content Delivery Network) for faster access.
Q: The product manager comes to you and says:
Hey, we have an 80-20 scenario here where 80 percent of the users are interacting with 20 of the tweets is there anything that you would change with the system design?
so, what we would want to do is maybe in the timeline generation service, the initial assumption is that we would arrange the tweets in a chronological order so you would want to tweak that algorithm where you're not only looking at the chronological order but also looking at the interaction on the tweet itself,
so you kind of have a weighted system in which your timeline is getting generated so the tweets that have more higher interaction get higher engagement automatically bubble up to the top of the user's timeline.
Q: How about in terms of like storage or caching for the tweets itself:
let's say that there's like a very small subset of tweets, but it's very popular, it's accessed very often, those tweets most likely would be some viral tweets or belonging to some influencers, so you would want to probably in your service over here cache those tweets and then inject them into the user's timelines at run time, generally What you're looking at is trying to cache the timeline itself and not per the individual tweet.
Tips for design system interview
system design interview is generally a very open-ended question there is no wrong answer there is no right answer there is a particular approach to solving the problem as long as you are able to validate or justify why you are making certain decisions, what is the reason behind them that should be good enough.
In these kinds of systems, you don't necessarily have the expectation, it is not that you need 30 minutes, 45 minutes to design something that Twitter or Facebook has designed over course of yours so that's not the goal for these types of questions the idea here is to kind of gauge how you are able to think so not getting bogged down in the lower level details but being able to think holistically of at a high level,
how the system will operate And not worrying about what the exact right answer for the system is, as long as you are able to justify and quantify your answers that should be good enough.
especially with how vague or ambiguous these questions are the interviewer wants to see how you can take those and then scope it into something that you can cover within 20-30 minutes or however long the interview is.
Refs:




